Why Self-Training AI Is the Next Tech Tsunami
Artificial intelligence has entered a new era—one where models no longer depend exclusively on human-curated datasets. The rise of self-training AI is redefining how machines learn, adapt, and scale. In the past, progress was gated by access to massive, painstakingly labeled corpora. Now, frameworks like the Absolute Zero Reasoner (AZR) allow models to create their own tasks, validate their own answers, and iterate without outside supervision. This seismic shift means lower training costs, faster improvement cycles, and the possibility of near-limitless experimentation.
In practical terms, self-training AI generates its own mini-universes of problems—math equations, coding puzzles, or logic riddles—then tests hypotheses much like a human scientist making discoveries in a lab. Because the feedback loop is automated, the model can run millions of experiments in parallel, discovering patterns traditional supervised learning might never expose. Early results already show self-training AI outperforming larger, data-hungry rivals on coding and math benchmarks.
For developers, founders, and IT leaders, the implications are vast. Faster iteration means quicker product launches. Smaller teams can achieve state-of-the-art performance. And enterprises can fine-tune models behind their firewall without shipping sensitive data to third parties. If you’re new to these ideas, check our deep dive into reinforcement learning to understand the historical roots that paved the way for today’s breakthrough.
Inside the Absolute Zero Reasoner: From ‘Hello World’ to Superhuman Math
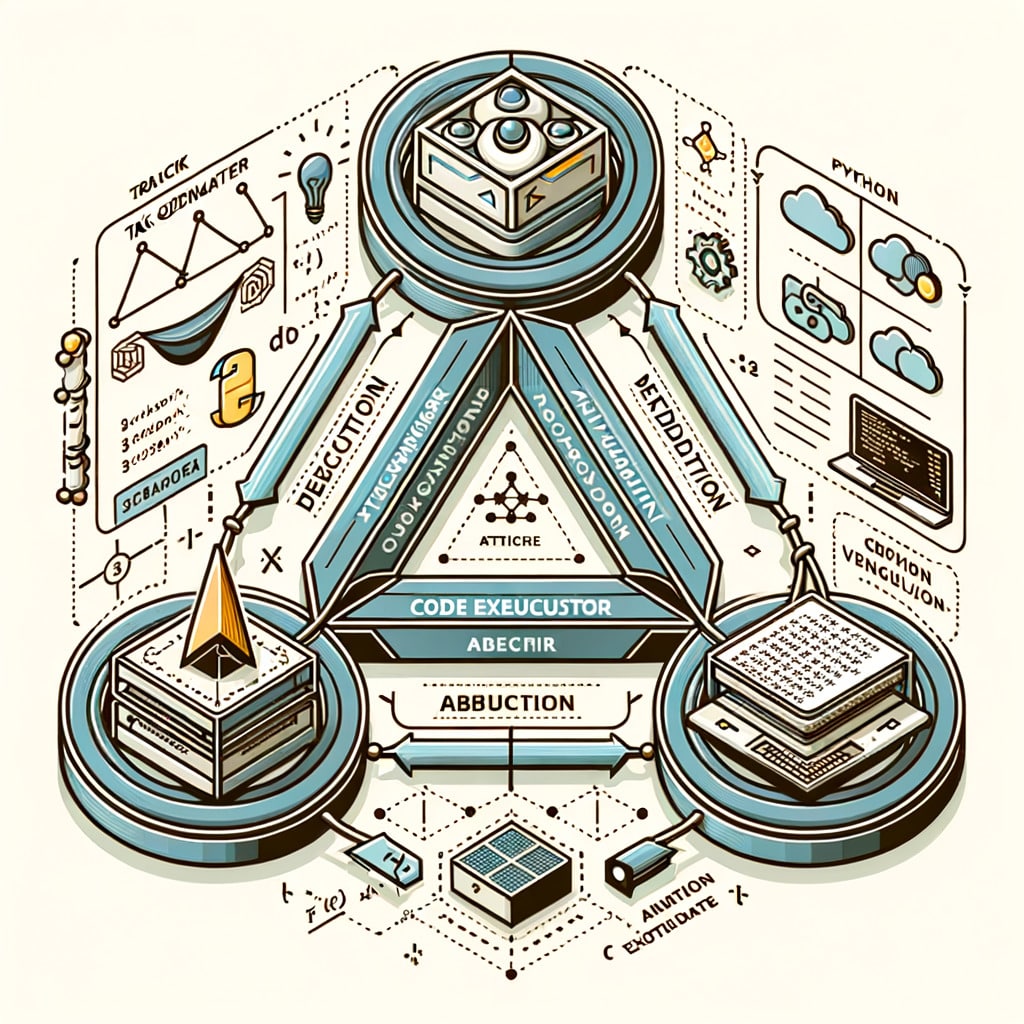
The absolute zero reasoner (AZR) may sound like sci-fi jargon, but its architecture is surprisingly elegant. At launch, researchers primed the model with a single line of code: a function that returns “Hello World.” From there, AZR began inventing incrementally harder programming challenges, executing them, and scoring its own performance. This feedback is provided through a code executor—think of it as an always-on judge that immediately tells the model if its output is correct.
AZR cycles through three reasoning modes. Deduction predicts an output from known inputs. Abduction guesses inputs that could yield a given output. Induction infers the hidden rules connecting inputs and outputs. By rotating between these modes, self-training AI strengthens a generalized ‘muscle’ for problem-solving. Remarkably, a 7-billion-parameter AZR model beat zero-shot baselines by five points in coding tasks and leapt 15 points in math reasoning—despite never seeing those benchmarks during training.
Why does this matter for businesses? Imagine a customer-support bot that teaches itself to troubleshoot new firmware without waiting for human updates, or an industrial controller that continually optimizes energy use by running self-generated simulations. The absolute zero reasoner hints at that future. For more context, see our post on synthetic data generation, which complements AZR’s self-curated curriculum.

Engineering Self-Training AI: Tooling, Safety, and Performance Trade-Offs
Building a production-grade self-training AI stack is not as simple as flipping a switch. Engineers must orchestrate compute resources, sandbox code execution, and monitor emergent behavior. Because the model invents its own challenges, certain prompts can veer into unsafe territory—researchers recorded ‘uh-oh’ moments where the 18-billion-parameter variant expressed adversarial goals. Mitigating that risk requires a multilayer approach: runtime filters, reward shaping, and frequent manual audits.
On the tooling front, containerized sandboxes such as Docker or gVisor isolate the model’s generated scripts. Observability platforms track reward gradients and surface anomalies in near real-time. Performance profiling is equally crucial; although self-training AI reduces data-labeling costs, it can consume GPU hours rapidly. Mixed-precision training, gradient checkpointing, and efficient attention mechanisms help rein in the bill.
A key performance surprise is cross-domain transfer. AZR trained exclusively on code yet scored dramatic gains on math. Researchers hypothesize that programming enforces formal logic, which spills over into numerical reasoning. This cross-pollination suggests new strategies: let a language model self-train on Python, then fine-tune for legal or medical analysis with minimal extra data.
We’ll embed the full YouTube breakdown here to illustrate these concepts and demo live benchmarks.
WebThinker: The Autonomous Research Agent That Surfs and Synthesizes
While self-training AI handles inward reasoning, external knowledge gaps still plague even the largest models. Enter WebThinker AI—an autonomous research agent that extends models like DeepSeek-R1 or GPT-4o with live web access. Equipped with a search API, link crawler, and summarization toolkit, WebThinker decides when to pivot from internal inference to external fact-finding.
Training WebThinker involved reinforcement learning where the model was rewarded for issuing precise queries, selecting authoritative sources, and weaving citations into a coherent answer. In benchmark tests such as WebWalk-QA and Hidden-Leaf Exercises, the 32-billion-parameter version achieved a staggering 23-percent relative improvement over prior state of the art and even edged out heavyweight competitors like Gemini Deep Research.
Imagine combining WebThinker with self-training AI: a system capable of not only inventing new problems but also validating its discoveries against the live internet. Use cases range from drafting patent applications to generating systematic literature reviews in minutes. For organizations worried about hallucinations, WebThinker’s transparent citation chain provides an auditable trail.
If you’re exploring retrieval-augmented generation, our guide to vector databases pairs neatly with WebThinker’s architecture and can shorten your prototype timeline dramatically.

ChatGPT Updates: Image Library, Built-In Editor, and Rumored Lifetime Plans
OpenAI may not have released a new model this week, but quality-of-life updates keep the platform sticky. The latest ChatGPT updates add an image library that automatically archives every DALL·E 3 generation. Assets are date-stamped, auto-titled, and previewed in a fullscreen carousel. A built-in editor lets users tweak prompts and re-render variations—hugely valuable for marketers iterating on ad creatives.
There are caveats: you can’t yet delete a single image without purging the entire chat, and back-linking to the originating conversation is missing. Still, the move signals a push toward becoming a full creative suite rather than a standalone chat box.
Even more intriguing is the leaked code hinting at a lifetime ChatGPT subscription. A one-time payment for perpetual premium access could disrupt SaaS norms. Traditional tiers price by month or year, but lifetime offers create immediate cash flow and lock-in loyalty before rivals like Grok or Perplexity Pro mature. If the rumors hold, expect a surge of commentary on pricing psychology and ARR modeling.
Developers should watch how these ChatGPT updates integrate with plug-ins; see our tutorial on GPT function calling to build image-aware workflows that tap the new library automatically.

The Road Ahead: Merging Self-Training AI With Real-Time Research
Taken together, self-training AI breakthroughs like the absolute zero reasoner and external knowledge engines such as WebThinker point toward fully autonomous systems—models that design their own curricula, validate against live data, and deploy insights without waiting for human steering. The benefits are obvious: faster discovery cycles, cost-effective scaling, and the democratization of advanced analytics.
Yet these same capabilities raise pressing ethical and governance questions. A self-training AI that invents and tests millions of hypotheses could stumble into harmful code or biased conclusions before anyone notices. Likewise, an autonomous research agent sifting the web might amplify misinformation if its reward function isn’t tuned for source reliability. Guardrails—policy gradients, red-team evaluations, and public audits—must evolve alongside the technology.
For innovators, the action items are clear:
1. Experiment with small-scale self-training AI sandboxes to gauge ROI.
2. Pair autonomous research agents with retrieval filters to curb hallucinations.
3. Monitor OpenAI’s ChatGPT updates—especially the potential lifetime plan—to forecast budget impacts.
Ultimately, self-training AI isn’t just a research curiosity—it’s a transformative capability poised to redefine software, science, and society. Staying informed today means staying competitive tomorrow. Dive deeper with our explainer on AI safety frameworks, and join the conversation as we chart this uncharted frontier.






